
While trying to read data from a table using the List Rows action of the Dataverse connector, we received the following error.
“Cannot write more bytes to the buffer than the configured maximum buffer size: 104857600”

At this point we had only provided the table name without any filter criteria and had not even provided a list of columns to retrieve, which means read all rows and data from all columns in each row
Per Microsoft docs, the maximum message size in Power Automate is 100MB. Here is the screenshot showing the limitation:

To overcome this limitation, one of the ways is to make sure you only request the required columns this will reduce the message size by skipping data that is not required for the current flow design
1. Request specific information:
You can retrieve ONLY those columns which are actually needed. It would really save time while retrieving the large-size data.
In power automate flow instead of retrieving N number of Account records with all columns, you can select only those columns that are actually needed/required.
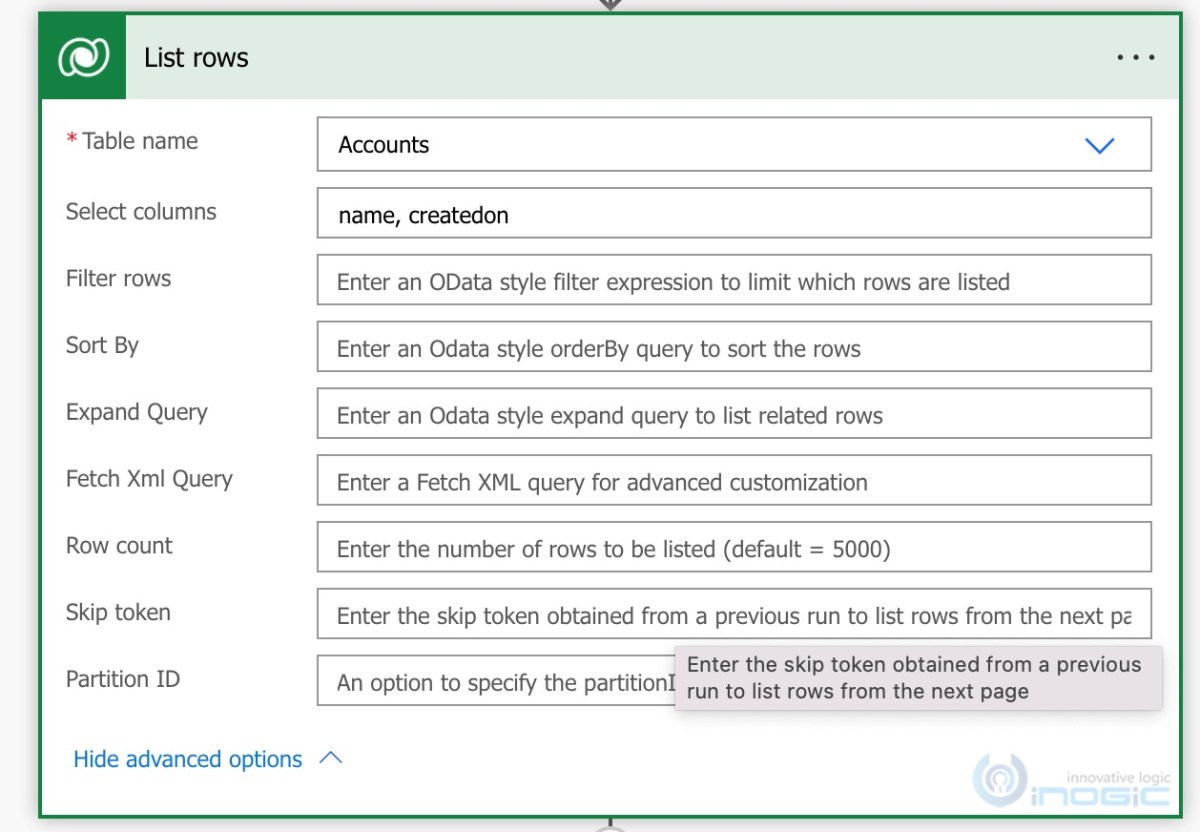
Once you add the minimum required columns (logical names of columns as shown in the below screenshot, I added Name and Created on columns), you will observe the time to retrieve those records has substantially reduced and would not exceed the buffer size limit.

You can further optimize the performance by specifying the filter criteria in the filter rows parameter. The filter conditions need to be specified as done for web api or odata queries. You can get more details here
Set the Row count, i.e the max records to be retrieved, top 50, or top 100 kind of requests.
While setting the specific column names and applying filter now lets this operation succeed, if the table has large dataset say over 5K records, it can take a while to complete this operation and yet only return 5000 records. Note if the row count is not set, the max limit of List Rows is 5000 records.

Note: It is not advisable to read large dataset and then loop through the result set using power automate flow as each step counts towards flow entitlements available per the licensing policies
2. Pagination:
If you would like to process a nightly schedule that retrieves certain records and processes them, and it might exceed 5000 records we could request for records in batches/pages. The List rows action provides an option to specify Skip token, as shown in the screenshot, this is the token to retrieve records from the next page. The logic for using skip token is explained here
Let us try to improve performance by reading the accounts (12K records) with pagination.
The skiptoken is returned in the result of List rows when Pagination from the settings is off. If there are more than 5000 records in the result, it returns the Next Link dynamic output which contains the token to be passed in the Skip token parameter the next time you call the List rows action.
After the List rows step add a step to read the Next Link value returned

The Next Link however returns the output in the following format
but what we need to pass in the Skip token property is only the skip token query parameter from the above i.e
%3Ccookie%20pagenumber=%222%22%20pagingcookie=%22%253ccookie%2520page%253d%25221%2522%253e%253caccountid%2520last%253d%2522%257bA5344CAE-C26E-EC11-8941-0022480AF35B%257d%2522%2520first%253d%2522%257b93C71621-BD9F-E711-8122-000D3A2BA2EA%257d%2522%2520%252f%253e%253c%252fcookie%253e%22
We need to parse this out from the url using a combination of expressions
Lets split the url by & to get each of the query parameter as an array element
split(outputs(‘List_rows’)?[‘body/@odata.nextLink’],’&’)
Note: I had to type out the outputs part in the above expression instead of chosing the dynamic property Next Link because that would return
outputs(‘List_rows’)?[‘body/@odata’]?[‘nextLink’]
and that would error because this results an empty string.
Now the skiptoken is added as the last query parameter, so we need to read the last element of the array. For this we get the length of the array – 1 is the index that we need to read the value from
sub(length(split(outputs(‘List_rows’)?[‘body/@odata.nextLink’],’&’)),1)
It isn’t easy to simply use – operator to perform the substract operation. We need to use the sub function as provided above. The first parameter being the value to deduct from and the second the value to be deducted.
You read the element from the array using the following
split(outputs(‘List_rows’)?[‘body/@odata.nextLink’],’&’)?[sub(length(split(outputs(‘List_rows’)?[‘body/@odata.nextLink’],’&’)),1)]
Finally we need to remove the $skiptoken= from the string to only get the cookie information that needs to be parsed. We decode the value as well to convert it into a readable format, it is easy to debug
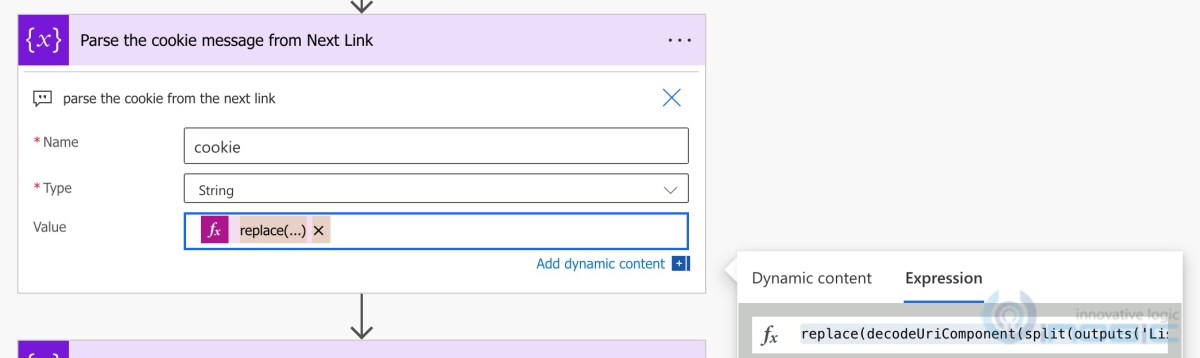
replace(decodeUriComponent(split(outputs(‘List_rows’)?[‘body/@odata.nextLink’],’&’)?[sub(length(split(outputs(‘List_rows’)?[‘body/@odata.nextLink’],’&’)),1)]),’$skiptoken=’,”)
As part of debugging exercise and to ensure the results of each of these expressions return what you need add 3 separate compose action with the output of the previous compose action being the input for the current one.
But since every step in a flow accounts towards the limits, it is important to reduce the steps in the flow as much as possible.
Now that we have combined all the functions and one single expression ready, we initialize a new cookie variable and set this expression
Upon successful execution it will return the following

Create a loopcount variable for debugging to maintain the count of loop processed to read all the records from the table.
Now that we have the skiptoken, we need to pass this in our next call to the List rows and we need to do this repeatedly until all records are fetched i.e the skiptoken is null
Add a Do until step after the above step with the condition to stop the loop when the skiptoken is null. Note for string variable the comparison should be done with empty as shown below instead of typing null function. (did this mistake and it went into infinite loop)

In the loop block we add the List rows and this time set the Skip token to the variable we have created to store the next page token.
After this run, the list rows action will again return NextLink token if more records exists. Check if token was returned and update the cookie with the new token received.
If no more records to read set the cookie to null which is our condition in the do until loop for it to break and exit the loop

The expression for parsing the cookie remains the same as the one used above. But remember this time you need to refer to the NextLink from the List_Rows_2 that we added in the do-until block
The above flow design will let you read all the records from the table. A test run for 12k records results in the following

The loop executed 2 times. The first time it returned 5000 records. And in the next one the remaining records as shown below

And no Next Link was returned

And it exits the loop.
Conclusion:
Optimize List rows action by specifying the list of columns to read and including a filter criteria and in case this would still result in more than 5000 records, pagination with the help of skiptoken will help in a more performant design.
Do note if you were to loop through the retrieve results i.e 12K rows, they count towards the available execution limits. Each step in a flow counts towards the licensing limits. Give it a thought if you really need to do it the flow way.

